강화학습
강화학습Reinforcement Learning 의 설명
-
쉽지만 추상적인 설명
- "시행착오를 통해 발전해 나가는 과정"
-
어렵지만 좀 더 정확한 설명
- "순차적 의사결정 문제에서 누적보상을 최대화하기 위해 시행착오를 통해 행동을 교정하는 학습과정"
순차적 의사결정 문제
강화학습이 풀고자 하는 문제 는 바로 순차적 의사 결정Sequential decision making 문제이다.
예시)
- 샤워하기
- 주식투자 포트폴리오 관리
- 운전
- 게임
보상
보상Reward이란 의사결정을 얼마나 잘하고 있는지 알려주는 신호, 그리고
강화학습의 목적 은 과정에서 받는 보상의 총 합, 즉 누적 보상 cumulative reward을 최대화 하는 것.
보상의 특징
- 어떻게 x, 얼마나 o
: 보상은 "어떻게" 에 대한 정보는 담지 않는다. 보상은 단지 내가 얼마나 잘하고 있는 지를 평가 해줄 뿐. - 스칼라Scalar
: 보상은 스칼라인 하나의 크기를 가진다. - 희소하고 지연된 보상
: 보상의 세번째 특징은 희소sparse 할 수 있으며 또 지연delay 될 수 있다.
에이전트와 환경
에이전트Agent가 액션Action(행동)을 하고 그에 따라 상황state 이 변하는 것을 하나의 루프loop 라 했을 때 이 루프가 반복되는 것을 순차적 의사결정Sequential decision making 문제라 할 수 있다.
- 현재상황 에서 어떤행동을 해야 할지 를 결정
- 결정된 행동 를 환경으로 보냄
- 환경으로부터 그에 따른 보상과 다음 상태의 정보를 받음
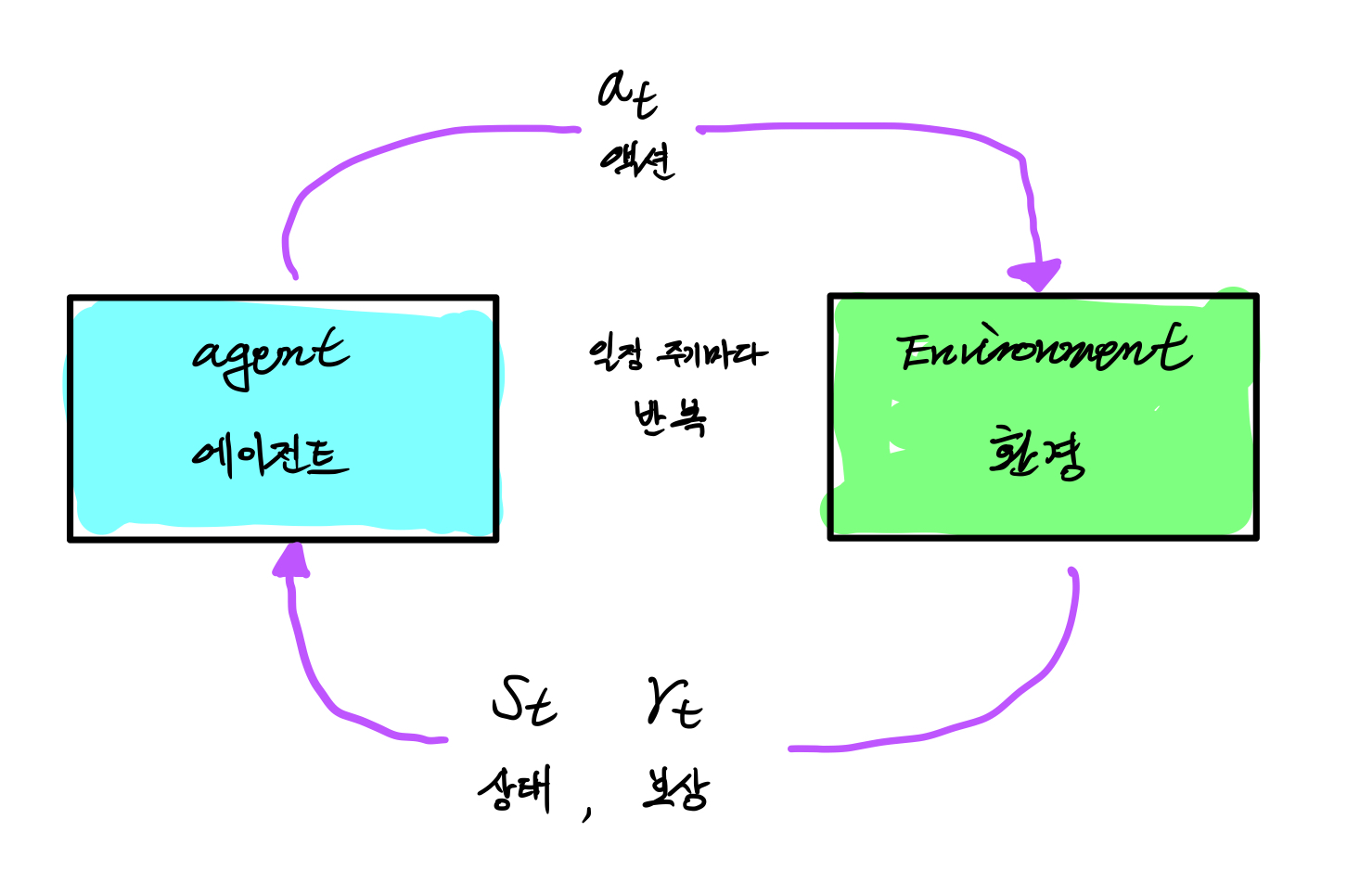
- 에이전트Agent로 부터 받은 행동 를 통해서 상태 변화state transition를 일으킴.
- 그 결과 상태는 로 바뀜.
- 에이전트Agent에게 줄 보상 도 함께 계산.
- 과 을 에이전트Agent에게 전달.
-
에서 시행 이를 통해 환경이 로 바뀌면,
즉 에이전트Agent와 환경Environment이 한번 상호작용하면 하나의 루프loop가 끝남.
이를 틱tick이 지났다고 표현한다. -
실제 세계는 이를 시간의 흐름이 연속적continuous으로 보겠지만,
순차적 의사결정문제에서는 시간의 흐름을 이산적discrete으로 생각한다.
이를 타임 스텝time step이라 한다.
강화학습의 위력
- 병렬성
- 자가학습 self-learning